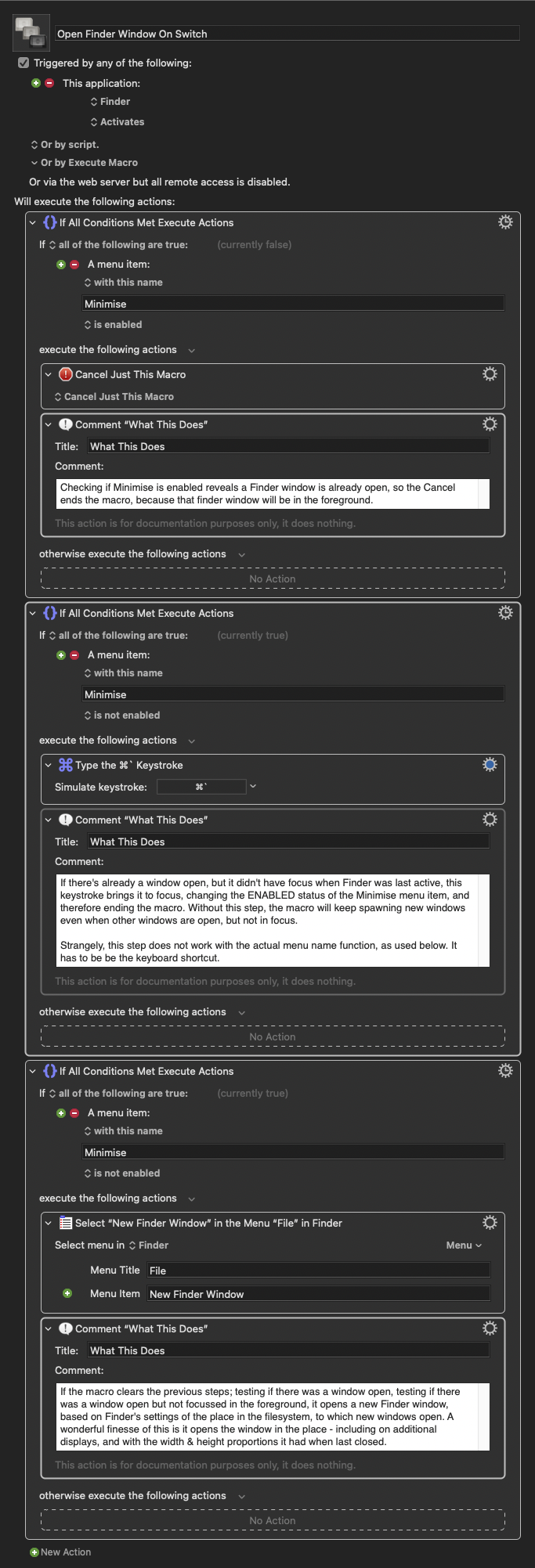
Finder in macOS has a behaviour that when you switch to it from another application, and there are no other Finder windows open in your current space, it should automatically open a new window to the user’s chosen default location.
Unfortunately, this behaviour isn’t reliable – it will do it once, but then not do it the next time. The problem being that if it fails to spawn the new Finder window when you switch to Finder, pressing the dock icon a second time will transport you to a different space that does have an open finder window.
Thankfully, Keyboard Maestro is here to save the day. To be clear, what really saved the day, was the Keyboard Maestro user forums, whose helpful denizens supplied the solution to this. Here’s the workflow, with documenting commentary included within.
This macro activates when switching to Finder from either the Dock, or by clicking on the desktop, and ensures you always have a file browser window ready to go when you switch to Finder.
That should seem like a obvious answer, right? Once an episode ends, the app stops playing, and remains so until the user interacts with it to manually play another episode.
That’s not the way the application behaves. What actually happens; if you have multiple episodes of a particular show on your device, stored locally within the Podcasts library, and you play one, all the remaining episodes will be put into the “Playing Next” queue. Each episode will be auto-played after the previous finishes.
So this is a setting to disable or enable Continuous Playback, that doesn’t have any effect on whether Continuous Playback happens, because Apple is a company that has no respect for the concept of Consent.
The user does not explicitly consent to Continuous Playback.
The user actively signals that they do not consent to Continuous Playback.
Yet, Apple goes ahead and does Continuous Playback to them, regardless.
Don’t ever leave your drink unattended with someone from Apple’s Podcasts.app team. Too harsh?
The purpose of a system is what it does.
The biggest company in the world, and the people who work there do not deserve the benefit of your doubt. They would fix this if they cared. They woud fix this if they found the idea of software ignoring user consent to be offensive in some way. They don’t, because they don’t.
Mona is a client application for Mastodon servers. It allows you to do all the things you can do on Mastodon, in a much better UI than a web browser can provide.
In intent, in its radically wide scope for user customisation, in its support for old devices back to iOS 12, in its single purchase / perpetual licence pricing structure, Mona is a fantastic application, especially as the result of a single developer. It is, quite simply, the best Mastodon client for someone in the Apple ecosystem.
Mona is better than vanilla Mastodon, in much the same way that Tweetbot was better than vanilla Twitter. It also furnishes capabilities the standard Mastodon experience lacks; quote-posts, for example. It doesn’t matter if mastodon.social doesn’t have an official quote-post format, if everyone uses a client that presents links to posts as if they were being quoted, your experience of Mastodon becomes one in which quote-posts exist.
Mona is what made Mastodonusable for me, in the same way that Twitter killing third party clients, like Tweetbot, made Twitterunusable for me.
What is it that makes a social media platform “usable”, in my eyes?
It comes down to this; a social media platform, which features chronologically delivered content, needs to have:
a native application on each of my devices, and
that application has to keep my reading location in my feed synchronised.
What do we mean by native application?
I’m not interested in using a web browser to view a social media platform, or a web page packaged in an application frame. I’m not interested in Electron “apps”; I want a Mac application for when I’m on my Mac, an iPad application when I’m on my iPad, and an iPhone application when I’m on my iPhone. As a side issue – I’m not interested in native apps for social media networks that are made by the social media network itself. Your social network is only as good as the third party apps it supports.
What I especially don’t want, is some “sortof works everywhere” compatibility technology second-class application on all three. Unfortunately, that’s what Mona is. Mona is a Catalyst app.
Catalyst is Apple’s version of Electron; only instead of allowing web pages to impersonate native software, it allows iPad apps to pretend they’re real Mac apps. Apple have supplied plenty of them on your Mac already, and it’s no surprise they’re the ones that feel off. They’re the janky apps that don’t have proper contextual menus with all the expected entries (like text transformation options), where spell checking doesn’t work the same, where the keyboard shortcuts don’t work right, where text selection of a single character with your mouse is difficult, where window resizing doesn’t look the way it does on your proper Mac apps. Apple’s Messages, Music, Podcasts, Books, Weather – all of these janky, brittle-feeling applications are so, because they’re iPad apps masquerading as Mac apps.
Mona is one of these, and shares all those characteristics. It’s better than using Mastodon in a web browser, but it’s worse than a proper Mac app. This is not because the developer is a bad person, or that the ideas behind Mona are bad ideas; it comes down to Catalyst being a badly implemented technology, which at its absolute best can only produce second-class applications on macOS.
For example, sometimes the main timeline in Mona will just stop accepting clicks. All the other tabs in the UI will be fine, however the main timeline will be scrollable, but inert. You can call up a second instance of the main timeline, it will be fine, but the only way to clear the problem, is to quit and relaunch the app. Sometimes, the app will return your timeline to where it was, sometimes it will return to the newest post in your feed. Then, you just have to try to remember how many hours ago you were at, and scroll back to that location. Unfortunately, there’s no feed location bookmarking, which would be really useful, because…
…feed synchronisation simply doesn’t work. Put it this way:
5 hours, syncs to 7 hours.
What these images are showing is that I was reading my Mastodon feed in Mona for Mac, and I had reached a point where I was 5 hours in the past, in terms of the posts I was reading. I moved over to my iPad, unlocked its screen, opened Mona for iPad, and after it did it’s “restoring iCloud Position” dance, it synced to a point that was 7 hours in the past.
Later in the evening, I tried again, this time going from my Mac to my iPhone:
1 hour, syncs to 6 hours.
This time I went from 1 hour in the past, to 6 hours in the past upon unlocking my iPhone, opening Mona, and waiting for it to “restore iCloud position”.
Or another attempt:
4 minutes, syncs to 4 hours.
…you get the idea.
To be clear, what is happening here is that Mona is saying it’s syncing my reading position on my iOS devices, to match where my Mac is at, and getting it wildly wrong.
What’s really problematic about this is that there’s no way to get the correct timeline position from my Mac, with the iOS device. If I look in the settings on the iOS devices, I will see that the last upload of Mona sync data to iCloud from my Mac was after I stopped advancing the timeline, and yet, for no good reason I can figure, Mona is picking some random (and inconsistent) time as it’s sync timecode.
Where this becomes a data-loss class issue, is that any interaction with Mona on the iOS device at this point overwrites my Mac’s timeline location. If I do any scrolling on the iOS device, it will push that timeline to iCloud, and my Mac will then jump to that location, if it is still awake with Mona on the screen.
I lose the correct data, by interacting with the incorrect data in any way.
If I swipe quit Mona on the iOS devices, and relaunch it at this point, it will load with its timeline set to the current moment, and then overwrite my Mac’s timeline location.
The only way to get consistent timeline sync is to have both devices open in Mona next to each other, and then advance the timeline on the source device, until the destination device reflects those changes. At this point the timelines will do the party trick of moving their timelines in unison.
Obviously, this isn’t a tenable situation – the whole point of iCloud Sync is that you can do something on one device, switch to another device any amount of time later, even if the original device is asleep or shut down, and just pick up where you left off. As far as I can recall, Mona is the only application I use which makes use of iCloud Sync, and consistently fails to correctly sync.
Whatever the reason, the point is that the Sync function doesn’t work in the real world. As a gimmick, making the timeline on one device move in realtime sync with another device is fine, but that doesn’t solve the problem of maintaining continuity of reading location as you switch between devices.
The other thing that bugs me about Mona, is the timeline compression that occurs after not using the application overnight. You sit down to Mona in the morning, to catch up on what’s happened in your feed overnight, and some inconsistent way on from your current location, is a Load More Posts label; after which, your feed continues from only 4 hours ago.
What inevitably happens as I sit there scrolling un-caffeinated, is I find myself suddenly wondering why I’m already at only 2 hours, and realise somewhere in my scrollback is a clickable link to load between 6 and 8 hours worth of posts. So I have to manually scroll back, until I find an image I recognise from last night, and then carefully find the single line Load More Posts link.
This wasn’t the behaviour of the app when I purchased it. For whatever reason, no matter how many times I’ve made this suggestion, the developer won’t do anything to either make this a behaviour that can be disabled, or make the Load More Posts label more obvious; like giving it a bright contrasting background colour, or a skeuomorphic broken, saw-toothed edge, which contrasts against the dominant horizontals and verticals.
It’s maddening, and a great example of how self-sabotaging people can be with their own work.
So that’s Mona (as of 24, October, 2024), an app that showed great promise in its early days for its massive, industry-leading customisability, which really pointed to a better direction for software which every part of the UI being user-modifiable, but which is now drowning under its basic technology not being up to the task, and its core feature – the literal reason you would use it, and not a browser; feed syncing, no longer actually working with any reliability.
It really does seem that no one is capable of making truly great software any more. Whether it’s building on janky non-native libraries, or image editor apps that are restricted to a single window with no tear-off palettes, or photo library apps that can’t have the thumbnails in one window, and the viewer in another, or full-screen preview software that can’t cope with having more than one display, everything seems to be collapsing to a world premised on no one using anything other than a single-screen laptop.
What has gone wrong with the culture of software development?
I’ve been listening to podcasts for over 20 years. The entire time, my collection has been subscribed, and managed within Apple’s iTunes.
No longer.
Podcasting is a medium under threat from a number of assailants:
Advertising agencies and “Podcast Networks” using Dynamic Ad Insertion: Advertising has shifted to “zero effort” pre-recorded ads, that are geotagged and invasively targeted to the listener. It’s a worse version of commercial radio advertising.
I was listening to a recent episode of a show on the “i heart radio” network (fetch my vomit bucket), and it had (if I recall) eight 30 second pre-recorded ads in a single break.
Prior to this development, podcast advertising was almost exclusively sponsor reads by the hosts of the show – you could enjoy listening to them, because the hosts would bring their own charm to the commercial.
Now you’re listening to a (typically) American or British show, and you suddenly get a broad Australian (in my case) accent pitching you McDonalds, or coal-fired power. So now, I skip ads reflexively.
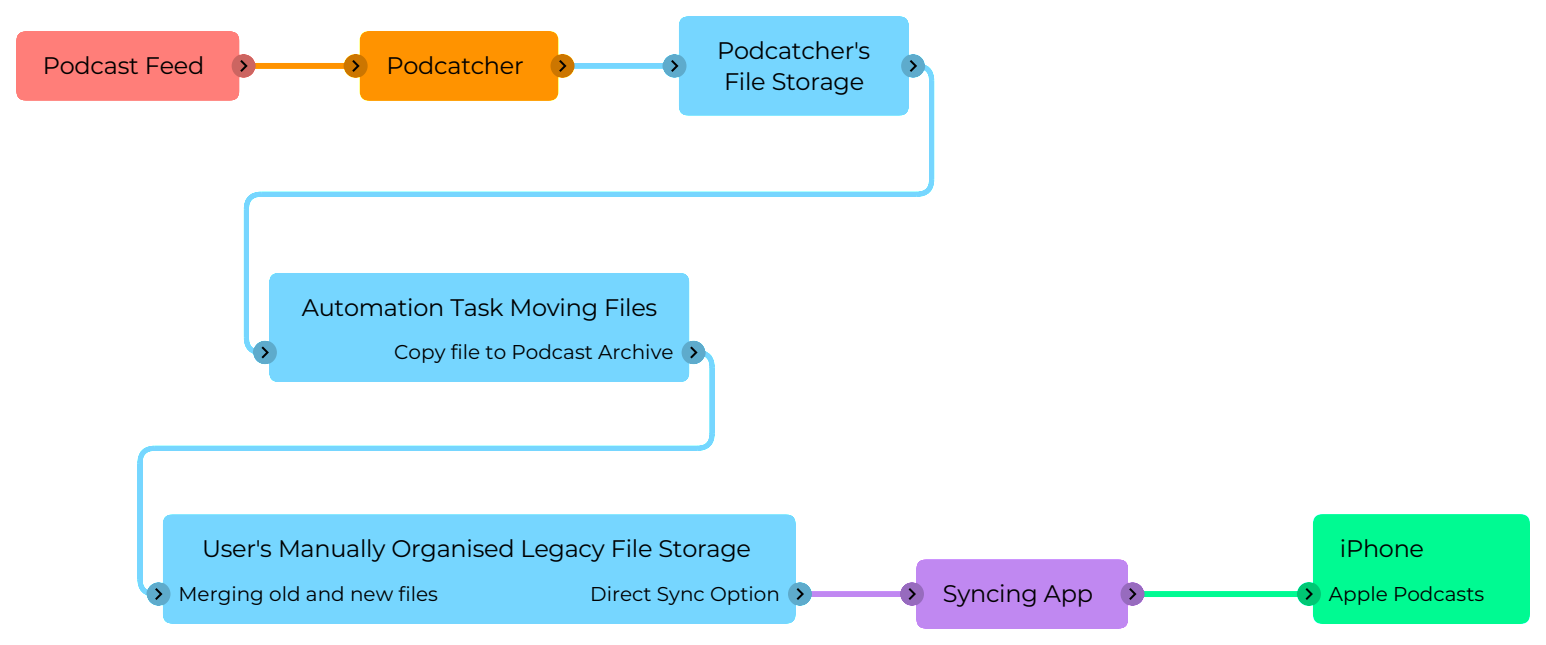
Independent Podcast Applications trying to do both too much, and too little: Every podcatcher & podcast player I’ve found so far, that run on Mac and iOS, are loaded up with recommendation garbage and show discovery, but won’t actually provide a competent interface or methodology for managing a locally-stored podcast collection*.
They all seem to presume that either no one collects podcasts, treating them as ephemerally as radio, or that everyone burns down their entire back-catalogue collection every time they change application, and just re-downloads everything from scratch. Every app features OPML export to migrate the feeds between apps, but no one provides a mechanism to migrate the downloaded episode library.
If you have files that aren’t attached to a feed, they’re effectively inaccessible, because none of the apps (from my experience) will let you just point to a directory full of files, and treat that as a show.
There’s also the sheer idiocy of using cloud services to sync the actual episode files themselves, tens or hundreds of megabytes in size, rather than just direct transferring them between devices. I think there has to be something profoundly wrong with you, if you think the way to move data a foot across a desk, is to round-trip it via a server on the other side of the world.
Apple: As the big dog in podcasting (though I note with significant schadenfreude that Spotify has apparently dethroned them), Apple is attempting to pivot from simply providing good applications, and a directory of shows, to selling subscription-based premium podcast feeds (and providing a mediocre podcast application).
To that end, Apple has stymied access to the location where Podcasts.app on the Mac downloads its files; using randomised strings for names of files and directories, therefore removing human readability. Worse still, it’s enforced location is on the boot drive – something that can’t be upgraded on almost all Macs, and for which Apple typically charges approximately four times the industry norm, per gigabyte**.
This comes after years of streaming-oriented changes to podcasts in iTunes, which made the process of keeping your files safe from auto-deletion more and more uncertain. It eventually required manually saving every single file, OR accepting a risk that if a feed moved and reposted its back catalogue to a new server, or changed the naming scheme for back catalogue files, iTunes would download the entire back catalogue again.
*Which excludes Overcast, because its entire basis is you rent space on Overcast’s servers, and store your collection there. However, I don’t build my archive plans on how long a single developer remains interested in continuing an app or business, nor on the volatility of server rental.
**I’ll note with some bitter irony that Mac OS X used to have human-readable plain text XML for all preference files, but they’ve been largely replaced with binary encoded versions that require a dedicated application to decode, and this regressive change was justified as saving disk space. Sure Apple, we’ll save a few megabytes so you can cheap out on the SSDs you put in machines, which you’ll fill to the brim with podcast files we used to keep on external drives.
So to hell with Apple.
Where to from here? Well, I’ve started by:
Manually copying all my podcast back catalogue episodes out of my old iTunes Music directory, into a new Podcast Archive: Everything there is organised in human-readable simple directory structures, with a folder for each show, and every episode in the appropriate place.
To deal with shows which have changed server, or changed their “album artist” or “artist” ID3 tags (which is what determines the name of the show / feed within the Podcasts.app), I’ve used a tag editor (MP3tag) to align all the previous episodes to the show nomenclature of the newest episodes.
For mass file renaming, to match the name schema of new downloads (because iTunes used to do strange things to filenames when saving podcast downloads), I’ve used Name Mangler.
For cases where the date created and modified of files are out of order, I’ve used A Better Finder Attributes to adjust things so that Finder’s view of the episodes can, by sorting as a list, reflect their original feed order.
Setting up a new podcatcher application:Doughnut – an open source podcatcher and player. It’s still relatively early in development, and seems to have become somewhat dormant, but it’s a workable, basic application that has no frivolous show discovery or non-core functionality. I’ve set up all my subscriptions in Doughnut that were previously active in iTunes. Doughnut downloads new episodes automatically to disk, but that doesn’t solve keeping them in my new Podcast Archive, since it can’t display existing files on disk – it only knows about things it has downloaded.
Transferring downloads to the Podcast Archive: Once Doughnut downloads a file, Hazel (a system automation tool) copies the file to the corresponding directory in the Podcast Archive.
The setup for this is pretty simple. In Hazel, I configure every folder Doughnut created for each subscribed show as an automated folder. I add an automation to each that has the rules; “File was created in the last 5 minutes”, and “move to (the Podcast Archive folder for that show)”. You could achieve this with the system’s built-in Folder Actions, or Shortcuts, etc.
The nifty thing about this is that since both the Doughnut directory structure, and the Podcast Archive are on the same logical APFS volume, the copy doesn’t use any more space – the two files are just references to the same thing, but behave as if they’re independent objects. Another advantage of this is if Doughnut has an issue, like randomly deleting files, it’s only acting on its downloaded copies, not your actual Podcast Archive. This of it as air-gapping your collection from the podcatcher.
Viewing the Podcast Archive: While I can just browse my files in Finder, in any of the traditional views, what if I wanted a more holistic overview of all my shows in the archive, in a single list, ordered by date? Remember SpotlightFinder searching, and Smart Folders / Saved Searches? A bunch of wonderful technologies that have sat, undercooked without full GUI support sine Apple bought Siri and realigned the company around the idiotic notion that a server on the other side of the world was the best way to search for things on your computer. What we do, is:
navigate to the root directory of the Podcast Archive
in the search field at the top of the Finder window, type a single space character. This non-discoverable and unintuitive action will bring up the GUI options for crafting your search criteria.
hit the plus sign
set up Kind, as Document, and then hit plus again
set Date Modified as however far back you want the list to show, if you want to limit the list; the last month, for example.
Save your search (I keep saved searches specific to a volume on the root level of that volume) and choose to add it to the Finder sidebar, because that makes it available for use in open / save dialogue boxes (normally, Smart Folders can’t be accessed through an open / save file browser).
Syncing to iPhone: Here we come to iMazing, which has the ability to copy files from Finder, directly into the Podcasts.app on your iOS device, without having to go the whole Finder sync procedure.
A word of caution; one of the goals of this process was to completely cut Apple out of my podcast life. When you install / first launch Apple’s Podcasts.app on iOS, it defaults to iCloud enabled, and downloads all your podcast subscription records from your iCloud account in the background before you interact with it. It is VERY hard to get rid of this once it’s in the app, so an important step within iTunes (or the Podcasts.app on Mac) is to:
Manually unsubscribe from every show to which you’re subscribed (and give that a few minutes to propagate to iCloud).
Switch off iCloud podcast sync on your Mac.
THEN delete Podcasts.app from your iPhone, nuking all its data with it.
Reinstall Podcasts.app on your iPhone, it should then load with an empty library because iCloud has no data for it.
Disable iCloud Sync in the settings app for Podcasts.
Now you’re ready to copy files with iMazing. One thing – you may encounter a bug where Podcast artwork isn’t copied across. As of mid-September, iMazing is aware of it, and are working on a fix.
And there you have it – you are now effectively back to the way things were when Podcasts were subscribed to in iTunes, and synced to an iPod. You lose a couple of things, like play counts, and synced playhead positions. However, iMazing’s drag & drop podcast loading (for which you can use your super-handy Smart Folders as your source) is a better workflow than the original iTunes sync. You also gain the ability to edit your podcast files (so those 10 year old adds for Lootcrate…) without worrying about breaking feed continuity.
There’s an issue I’ve encountered a couple of times lately, where the SMTP server for an account will report in Connection Doctor that it doesn’t need authentication (even though it does) and fail to send mail.
There appears to be no solution to this, as all the settings will be correct, the only option is to delete the account in mail.app, and recreate it from scratch. Deleting just the SMTP server profile does not appear to be sufficient to do the job.
I realised recently that in the changeover to my new workstation, and the change to new operating system versions, my entire workflow for producing a Surfing The Deathline page art errata fix was broken.
Worse still, I couldn’t fit the entire thing in my head at once, so there was nothing for it, but to start mapping the whole thing out.
The process:
Adobe Indesign CS5.
Output all pages to individual .pdf files
Adobe Photoshop CS5.
Convert each page to .png, and .jpg files
Automator Workflow.
Rename files and copy them to the appropriate development folders
Chronosync Workflow.
Copy a subset of files to be used in the extract versions to the appropriate extract development folders.
A thought that occurs is to put the entire process into the Virtual Machine I’m using to run the Adobe apps, so that they’re sealed off against change.
This year my old Mac Pro running macOS 10.13 High Sierra shuffled into the grave. I needed a newer computer quickly, and my options were either Apple-Silicon Mac Studios, or secondhand 2019 Mac Pros.
For reasons, I bought the Mac Pro.
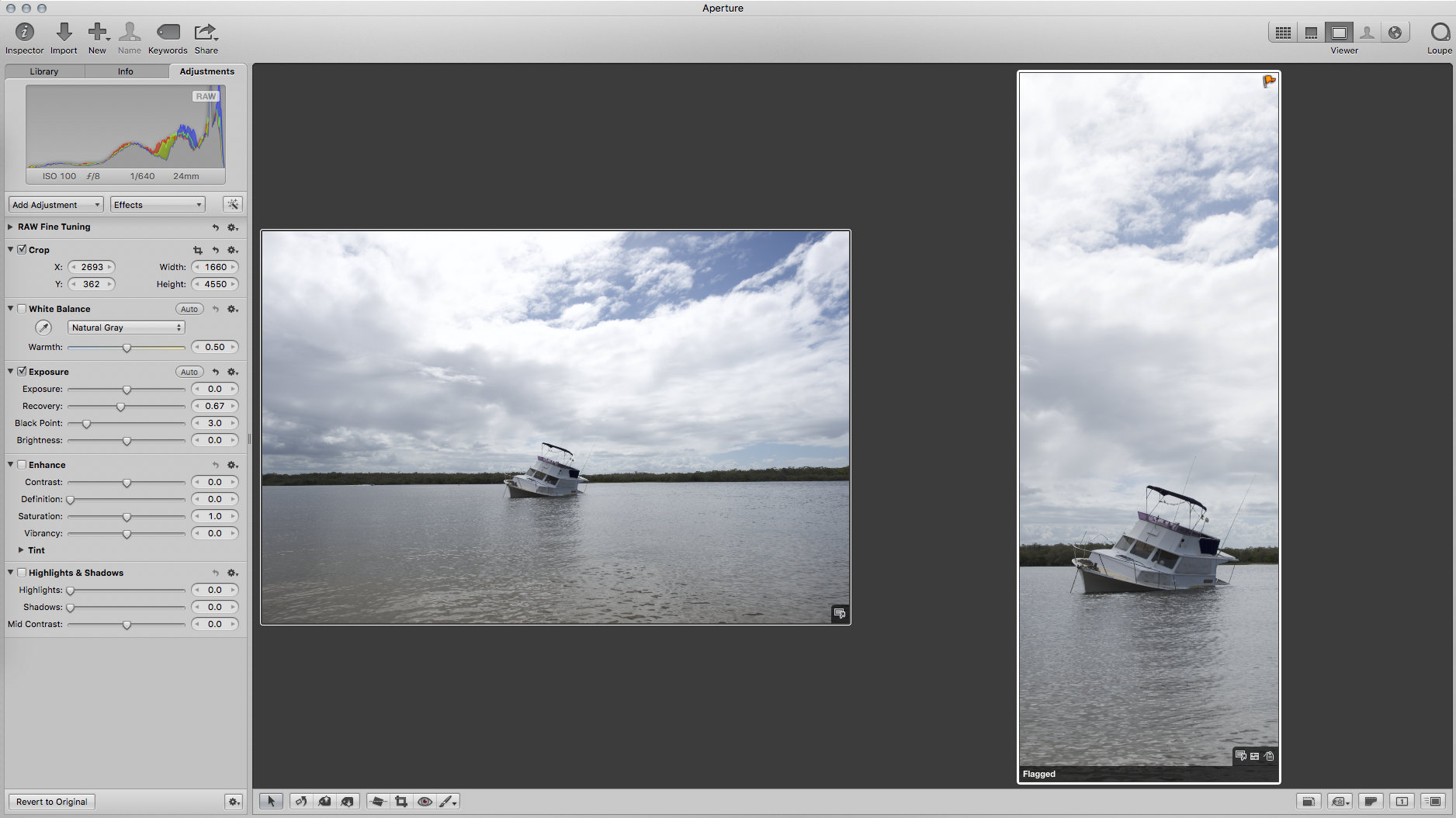
This new machine runs macOS 13 Ventura, and that’s a problem, because it has broken my entire photography workflow, which was based around Apple’s Aperture Digital Asset Manager.
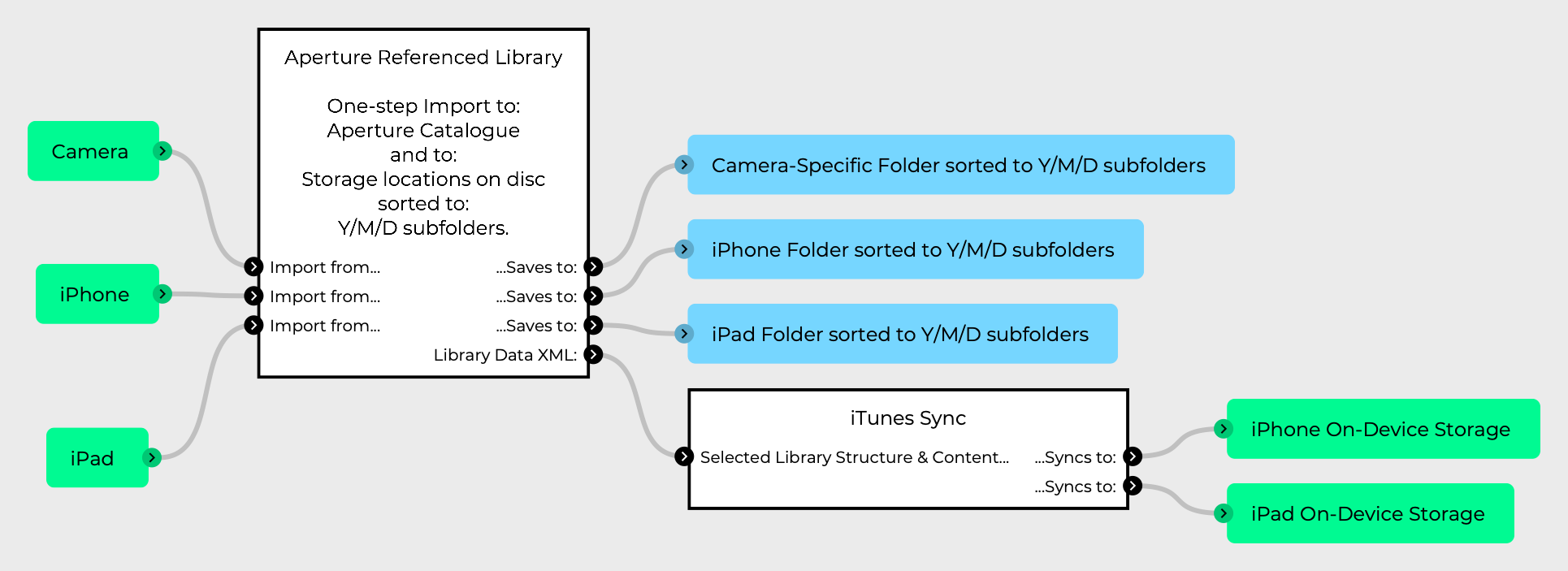
Here’s a diagram of how my photo management worked with Aperture, my cameras, and my iOS devices:
The import, to library, to sync workflow was pretty simple:
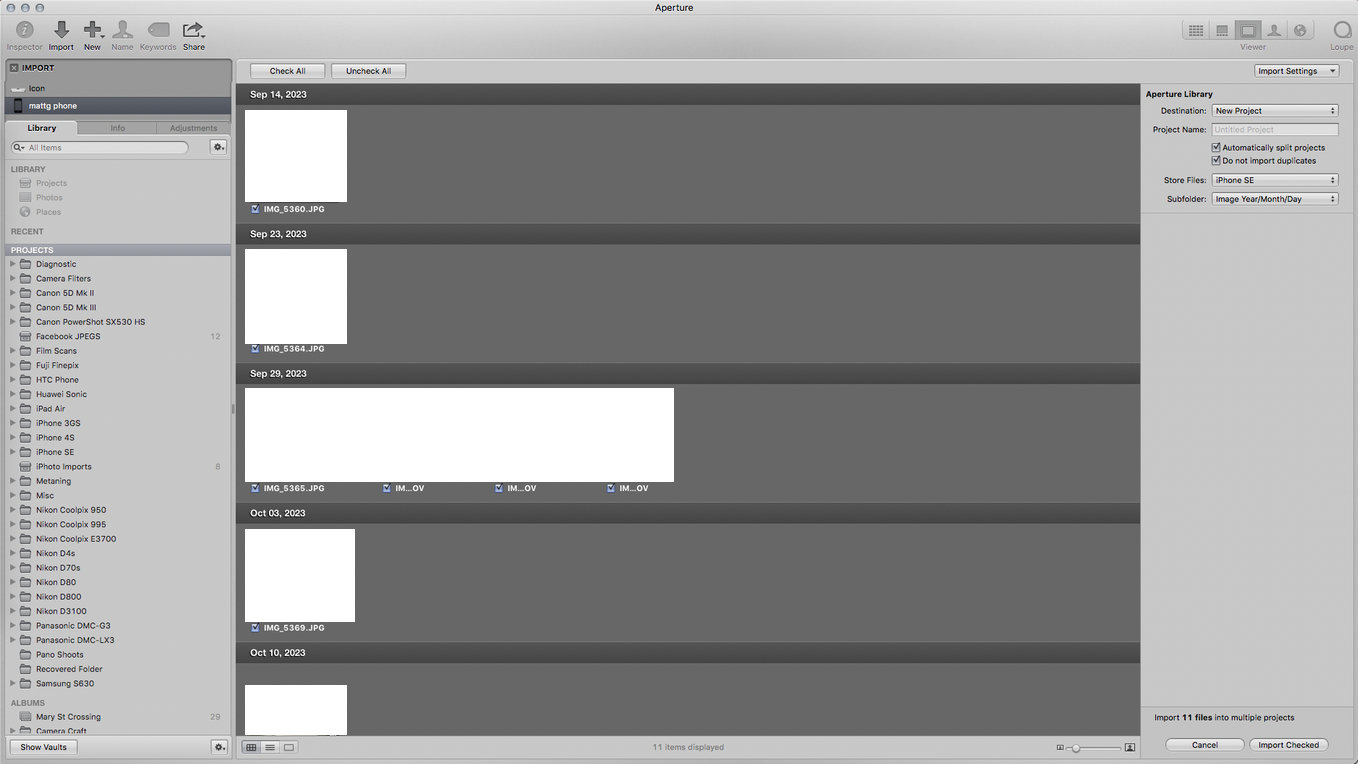
Plug the camera or device into the computer.
Select the images you want to import.
Choosing images.
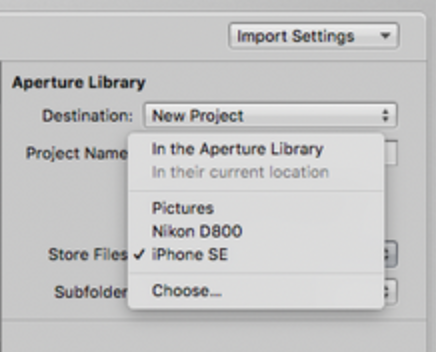
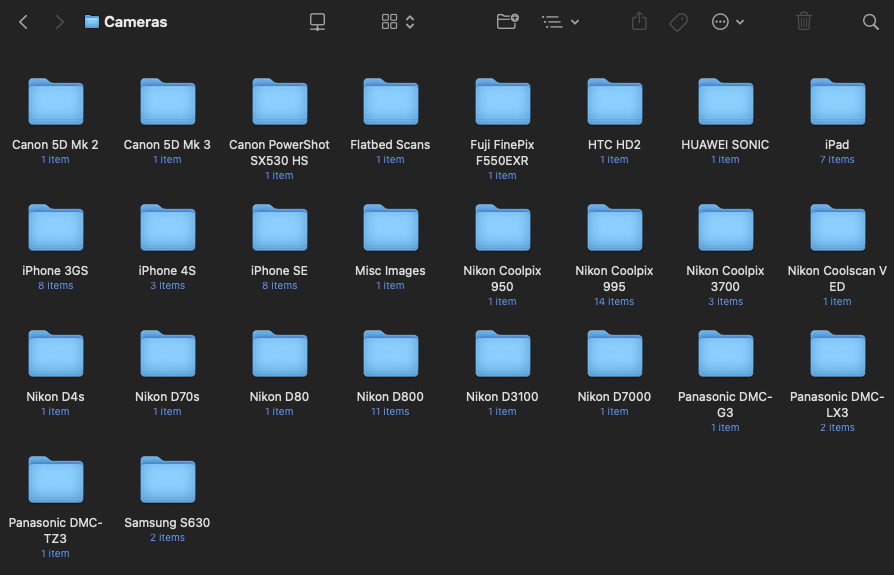
Choose where you want the images copied to on disc (this is populated by use, so would eventually have all the folders shown in the filing structure). I choose to keep them organised by device.
Choosing a destination on disc.
Filing structure.
Aperture copies the files to disc, placing them in Year / Month / Day subfolders.
File storage on disc.
Aperture creates events in the Aperture catalogue, which correspond to the shooting sessions.
Events created in the Aperture catalogue.
From there you can:
Manage your images in the catalogue.
Organising in the Aperture catalogue.
Edit images.
Automatic version stacking
Multiple image viewing
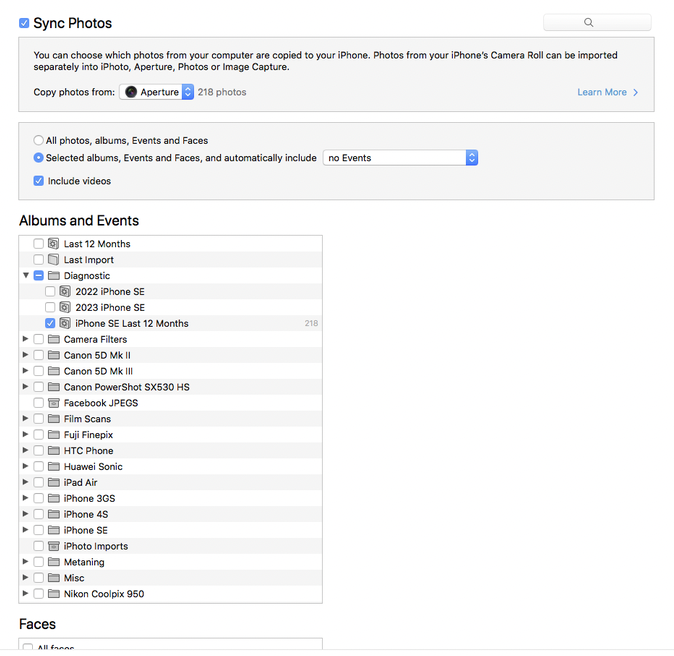
Sync images back to your iOS devices.
Sync back to iPhone
What Went Wrong?
This process doesn’t work in Ventura. For a start, Aperture won’t run by default under Ventura. There’s Retroactive, which purports to modify older Apple apps to run on the new operating systems, but it isn’t working for me (images won’t display). iTunes doesn’t work either (Retroactive excepted) but that has a replacement in Finder sync. Aperture’s loss is a real pill, however, because in its wake there is no tool that can do all the things it was capable of doing.
One option to keep these older tools working, is to use them via virtual machines. Aperture will run in a VM, and all of its import and organisation utility seems to function correctly. One thing it cant do however, is display full-size images. This is due to a lack of support for virtualised GPU access, in the versions of macOS which support Aperture.
Apple Photos:
Photos was supposed to be a replacement for iPhoto and Aperture, however there are some significant shortcomings. Namely:
Photos cannot import from device to a referenced library structure – in other words it can’t move files from device, to your choice of storage location.
It can import to a referenced library if the files are already in their final storage location.
Photos importing to a managed library structure destructively renames files when it stores them in its internal storage location.
So Photos fails on that first instance – it can’t be the universal ingestion tool to get my images off my devices, unless I want to give up my entire file management structure, and accept my files being destructively renamed.
Nope.
There’s also the matter of bitten once, not going to be bit again. After investing in an Apple solution for this whole process, I don’t want to trust the company with a concentration of functionality. You can never know what core features might disappear from the software, because someone in the company has an office politics agenda to change its direction.
There is another ingestion option, and it’s…
Image Capture:
Image Capture is a very old application, which can import from any device, to any location. This would seem ideal, except for one shortcoming:
No subfolders.
Image Capture can only import to a flat folder location – no Year / Month / Day sub folders. This brings a crisitunity in that it forces me to rethink just how much of my process I invest in any one application, and maybe break the process down, so as to ensure no one application can own the entirety of my photo management process.
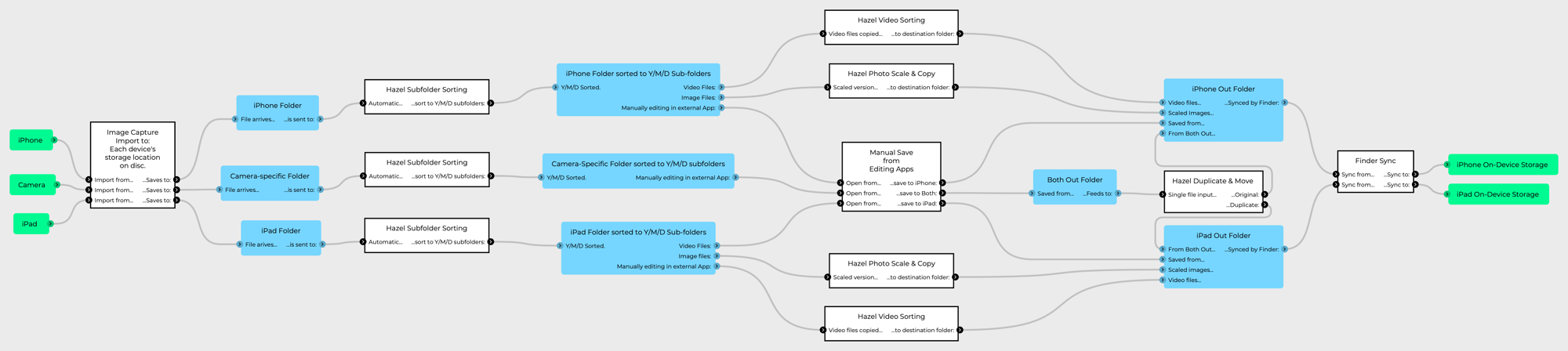
The New Workflow:
The glue of the new workflow is Hazel – an automation system I’ve been using for a while, which is effectively a more reliable version of Apple’s Folder Actions. Thus:
This is a much more complicated pipeline at first glance. However, it has a high degree of modularity, and actually allows for flexibility the old system lacked. For example, the integration of manual saving of edits. Instead of having to save from an editor, then re-import to Aperture etc, the edit can happen in any application.
This also provides a framework for Digital Asset Managers to be connected in. CMYE’s Peakto looks to be an interesting meta-manager, which can look inside other DAM libraries. Photos is also an option, since one of the things Hazel can do is to automatically import images to the Photos library, so in that second round of Hazel processing after the images are in their Y/M/D folders, there could be an “import to Photos” process.
However, I refuse to trust Photos to continue support of referenced libraries, so it’s probably better to not start with it at all.
Zero DAM:
There’s also an interesting alternative to get things working quickly, and that’s not using a DAM at all, but just saving search criteria as smart folders in the filing structure where your images are kept:
In this system, you’d simply never need to use the DAM for a main catalogue – Finder can do most of the tagging etc for you, and then you can use dedicated editing DAMs like Capture One when you want versioned editing on a single file.
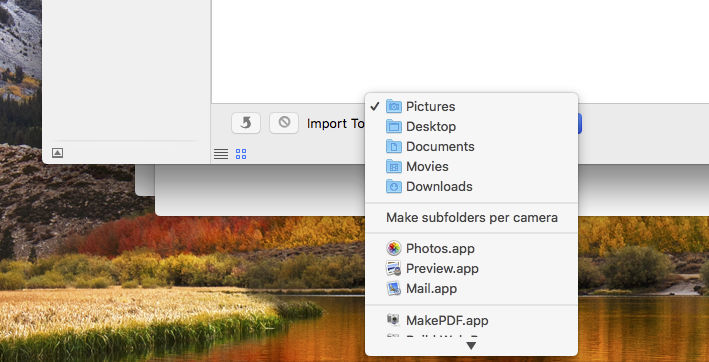
Image Capture is an application included with macOS, which acts as a general image ingester, and scanner interface. You plug a device in, and Image capture looks at all the files available on it, then gives you the option to download them to your chosen location, or application.
The basic UI, is this:
Image Capture in macOS High Sierra
Or at least, that’s how it looked.
The most salient point is that option “Make subfolders per camera”. What that does when checked, is that whatever folder you choose to copy files into, Image Capture will first make a folder with the name of your device. Great if you’re copying images in for the first time, but if you already have a previously established folder for device images, not something you’d want to have enabled.
What went wrong:
In recent versions of macOS, this checkable menu option is no longer visible, which means you lose the ability to control that aspect of the software, and the default is to create the device subfolder. *eugh*
Anyway, a bit of research online indicted tht the setting might be controlled in the .plist file for Image Capture, located at:
~/Library
/Preferences
/com.apple.Image_Capture.plist
…and sure enough
The nefarious property
Fir enough, I’ll open it in a text editor, and just change <true/> to <false/>
Except… it’s a binary .plist file, and opens as garbage text. Yes, only Apple could make a plain text XML preference file system, into binary files that require a special developer tool to modify them.
So, off to the Mac App Store, and there’s a simple tool PLIST Edit. $10, done.
Open the plist file in it, change the value to False, save, relaunch Image Capture, and:
There’s a problem I encountered with Mac-based filesharing over SMB where HFS+ and APFS formatted disks would behave differently from each other when mounted remotely.
While HFS+ disks worked as expected, APFS disks would have issues with write permissions – everything would look correct, but creating folders would result in folders that couldn’t be written to, or renamed.
All the disks had the same permissions and setting on the file server – all had:
(Machine Admin user): Read & Write
staff: Read & Write
everyone: read only
And they were set to “Ignore Ownership”.
That ownership issue appears to be the problem – I had to enable ownership for the APFS volumes, and then add a dedicated filesharing user to the file server, add that user with read & write permissions to the APFS drives, and then apply permissions to the enclosed items.
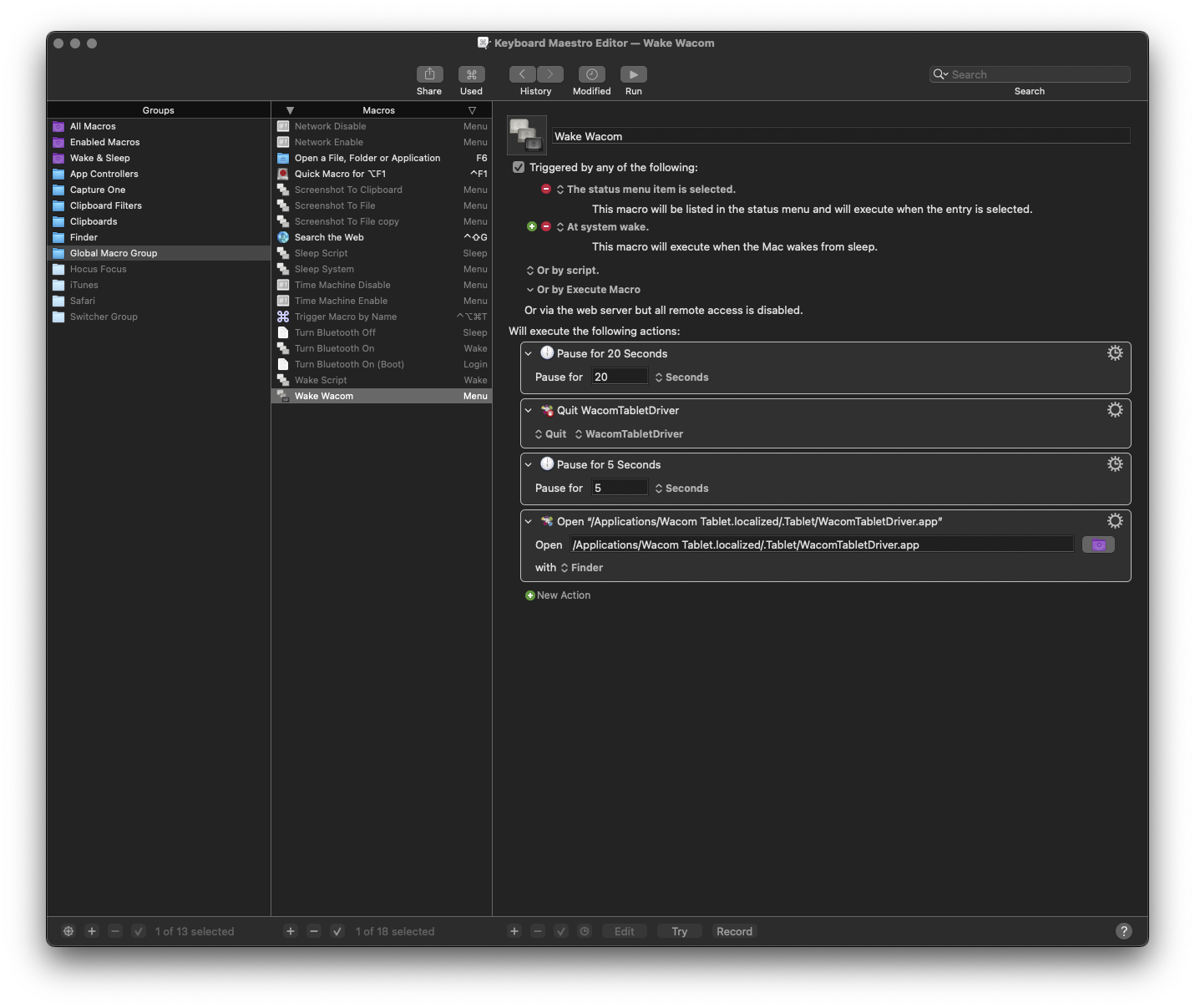
Among the various changes happening in macOS under macOS 13 Ventura, is a problem with Wacom’s Intuos 4 graphics tablets. Following is a way to use Stairways Software’s Keyboard Maestro to solve the particular glitch thrown up by this hardware / driver / operating system combination.
The Symptom:
Upon waking from sleep, the OLED screens on larger size Wacom Intuos 4 tablets my be unresponsive. While all the hardware appears to function, and the controls for the screen brightness are accessible, the screens themselves remain inert.
The Cause:
The problem appears to be a result of the driver not working correctly over the sleep / wake cycle.
Troubleshooting:
I contacted Wacom support, and despite their driver notes showing device compatibility for my tablet clearly written:
…the support representative claimed that the Intuos 4 XL became unsupported after the previous driver, which does not support macOS Ventura.
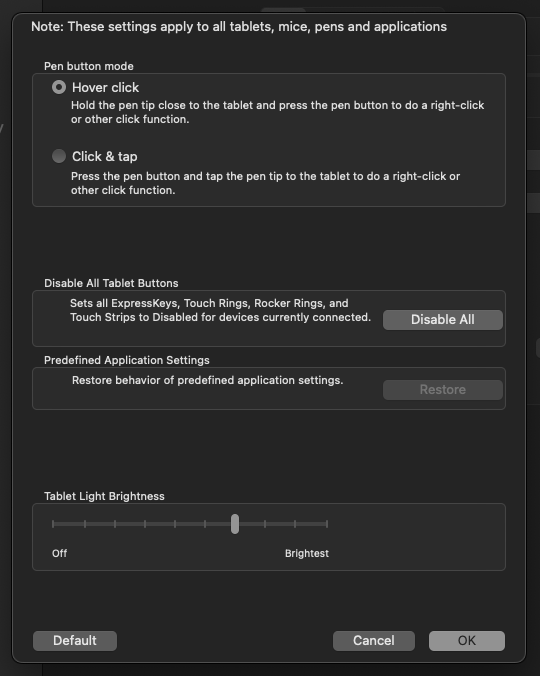
To be clear, if it’s “unsupported”, one would question why the driver settings show this:
…that “Tablet Light Brightness” feature? Those OLED screens were removed from Wacom tablets after the Intuos 4. There are no newer tablets with those screens, so if the tablet isn’t supported by the driver, why is that there?
We could also check out the Wacom Centre app, which is used to… well it doesn’t really seem to do anything necessary. It’s effectively a thing that checks for driver update status, and provides shortcuts to the Wacom System Settings pane.
That’s “unsupported”? Really?
So on to…
The Solution.
Fixing this problem is a simple matter of quitting and re-launching the tablet driver. You can use Wacom Tablet Utility to do this manually, or you can use Keyboard Maestro to add a set of events to do this as a menu command, or as something that runs automatically upon wake, thus:
So what this macro is doing is it’s triggered by either the Keyboard Maestro menulet app, OR triggered by waking up from sleep. It waits 20 seconds, so that the wake process is out of the way and settled if it’s triggered by a Wake event, then it quits the driver, waits, and launches it again. You’ll need to reveal hidden files and folders to navigate to it, in order to populate the app’s location.